[#1-1] Microbiome 연구에서 그룹당 몇 개의 Sample이 필요할까?
Microbiome 분석에서 그룹 비교를 진행하거나 분석 의뢰를 받을 때 자주 듣는 질문이 있습니다.
“그룹당 몇 개의 샘플이 있어야 할까요?”
그래서 오늘은 이 질문에 답하기 위해 관련 논문을 함께 살펴보려고 합니다.
이번에 읽은 논문은 Kers와 Saccenti가 2022년에 발표한 The Power of Microbiome Studies: Some Considerations on Which Alpha and Beta Metrics to Use and How to Report Results입니다.

출처: Kers and Saccenti (2022), CC BY.
이 논문은 microbiome 연구의 sample size와 diversity metric 선택 문제를 함께 다룹니다. 내용이 많기 때문에 두 편으로 나누어 정리해보려고 합니다.
- Microbiome 연구에서 그룹당 몇 개의 샘플이 필요한가?
- Alpha diversity와 beta diversity metric은 어떤 기준으로 선택해야 하는가?
이번 글에서는 먼저 sample size를 중심으로 살펴보겠습니다.
1. 우리는 왜 충분한 수의 샘플이 필요한가
논문을 작성하거나 분석 보고서를 만들 때 우리는 결국 그룹 사이에서 의미 있는 차이를 찾으려고 노력합니다.
예를 들어 건강한 사람과 특정 질환을 가진 환자의 gut microbiome을 비교한다고 가정해보겠습니다. 두 그룹의 미생물 조성이 실제로 다르다면, 수집한 데이터를 이용해 그 차이를 발견하고 설명하고 싶을 것입니다.
그런데 우리는 전 세계에 있는 모든 환자와 건강한 사람을 조사할 수는 없습니다. 현실적으로는 이들을 대변할 수 있는 일부 대상자를 모집하고, 두 그룹을 만든 뒤, 이들의 데이터를 이용해서 분석합니다.
통계에서는 우리가 알고 싶은 전체 관심 대상을 모집단(population), 모집단을 대변하기 위해 실제로 관찰한 일부 대상을 표본(sample)이라고 합니다.
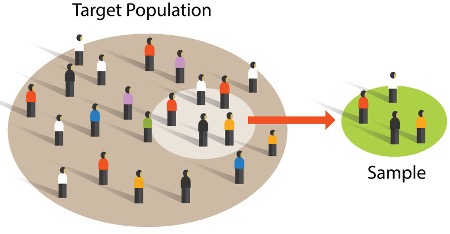
예를 들어 질환자의 gut microbiome 특성을 알고 싶다면 전 세계의 모든 질환자가 모집단입니다. 실제 연구에 참여해 샘플을 제공한 질환자 30명은 표본입니다. 우리는 이 30명의 데이터를 바탕으로 모집단의 특성을 추정합니다.
표본은 모집단의 일부이기 때문에, 표본에서 관찰한 결과가 모집단의 실제 특성과 완전히 같을 수는 없습니다. 우연히 특정한 특성을 가진 샘플이 많이 포함될 수도 있고, 그룹 내부의 개인 차이가 크게 나타날 수도 있습니다. 이를 표본 추출 오차(sampling error)라고 합니다.
샘플 수가 너무 적으면 우연에 의한 흔들림이 커집니다. 반대로 샘플 수가 충분하면 표본이 모집단의 특성을 비교적 안정적으로 반영할 가능성이 높아집니다. 일반적으로 충분한 수의 샘플을 확보한 연구일수록 결과의 신뢰도도 높아집니다.
하지만 연구에 사용할 수 있는 시간과 예산은 제한되어 있습니다. 따라서 실제 연구를 설계할 때에는 그룹 비교가 가능한 최소한의 샘플 수를 고민하게 됩니다.
2. 통계적 유의성이란? p-value 0.05가 도대체 뭐길래
샘플 수를 이야기하기 전에 먼저 통계 검정을 간단히 살펴보겠습니다.
두 그룹을 비교할 때 흔히 확인하는 값이 p-value입니다.
p-value의 p는 probability, 즉 확률을 의미합니다. 우리말로는 유의확률이라고 합니다.
통계 검정을 시작할 때에는 보통 “두 그룹 사이에 차이가 없다”라는 귀무가설(null hypothesis)을 세웁니다.
p-value는 귀무가설이 참이라고 가정했을 때, 현재 관찰한 차이 또는 그보다 더 극단적인 차이가 우연히 나타날 확률입니다.
예를 들어 p-value가 0.03이라면, 실제로 두 그룹 사이에 차이가 없다고 가정했을 때 지금과 같은 수준의 차이가
우연히 관찰될 확률이 약 3%라는 의미입니다. 여기서 주의할 점이 있습니다.
- p-value는 귀무가설이 참일 확률이 아닙니다.
- p-value가 작다고 해서 차이가 크거나 생물학적으로 중요하다는 의미도 아닙니다.
- p-value는 sample size, 그룹 내부 분산, effect size의 영향을 함께 받습니다.
많은 연구에서는 p-value가 0.05보다 작을 때 통계적으로 유의하다고 판단합니다. 이 기준값을 유의수준(alpha)이라고 합니다.
하지만 실제로 차이가 있는데도 샘플 수가 부족하면 p-value가 충분히 작아지지 않을 수 있습니다. 의미 있는 차이를 놓치는 것입니다.
3. 간단한 숫자로 살펴보는 p-value의 함정
p-value는 단순히 평균 차이만으로 결정되지 않습니다. 샘플 수(sample size)와 그룹 내부 데이터의 흩어짐, 즉 분산도 함께 영향을 줍니다.
간단한 숫자와 t-test를 이용해 살펴보겠습니다.
예시 1. 평균 차이가 3인 두 그룹
1
2
3
4
A <- c(1, 2, 3)
B <- c(4, 5, 6)
t.test(A, B)
| Group | 관찰한 값 | Sample size | 평균 | 표준편차 |
|---|---|---|---|---|
| A | 1, 2, 3 | 3 | 2 | 1 |
| B | 4, 5, 6 | 3 | 5 | 1 |
A 그룹과 B 그룹의 평균 차이는 5 - 2 = 3입니다. 양측 t-test의 p-value는 약 0.0213입니다.
일반적으로 사용하는 유의수준 0.05보다 작기 때문에, 이 예시에서는 관찰한 평균 차이가 단순한 우연으로 발생했다고 보기 어렵다고 해석할 수 있습니다.
예시 2. 평균 차이는 같지만 sample size가 증가한 경우
이번에는 같은 숫자 패턴을 한 번 더 반복해보겠습니다.
1
2
3
4
A <- c(1, 2, 3, 1, 2, 3)
B <- c(4, 5, 6, 4, 5, 6)
t.test(A, B)
| Group | 관찰한 값 | Sample size | 평균 | 표준편차 |
|---|---|---|---|---|
| A | 1, 2, 3, 1, 2, 3 | 6 | 2 | 약 0.89 |
| B | 4, 5, 6, 4, 5, 6 | 6 | 5 | 약 0.89 |
평균 차이는 여전히 3입니다. 그런데 p-value는 약 0.00017로 작아집니다.
1
0.0213 -> 0.00017
실제로 독립적인 샘플 수가 많아지면 평균에 대한 추정이 안정됩니다. 따라서 평균 차이가 같더라도 더 작은 p-value를 얻을 수 있습니다.
예시 3. 평균 차이는 같지만 데이터의 폭이 넓어진 경우
이번에는 모든 값을 양수로 유지하면서 그룹 내부 데이터의 폭을 넓혀보겠습니다.
1
2
3
4
A <- c(2, 7, 12)
B <- c(5, 10, 15)
t.test(A, B)
| Group | 관찰한 값 | Sample size | 평균 | 표준편차 |
|---|---|---|---|---|
| A | 2, 7, 12 | 3 | 7 | 5 |
| B | 5, 10, 15 | 3 | 10 | 5 |
평균 차이는 앞선 예시와 동일하게 10 - 7 = 3입니다. 하지만 p-value는 약 0.503으로 커집니다.
그룹 내부의 값이 넓게 흩어져 있으면 관찰한 평균 차이가 그룹 간 차이 때문인지, 데이터 자체의 변동 때문인지 판단하기 어렵습니다. 따라서 같은 평균 차이라도 p-value가 커질 수 있습니다.
예시 4. 데이터의 폭은 넓지만 sample size가 증가한 경우
마지막으로 폭이 넓은 데이터 패턴을 반복해 샘플 수를 늘려보겠습니다.
1
2
3
4
A <- rep(c(2, 7, 12), 10)
B <- rep(c(5, 10, 15), 10)
t.test(A, B)
| Group | 관찰한 값 | Sample size | 평균 | 표준편차 |
|---|---|---|---|---|
| A | 2, 7, 12 반복 | 30 | 7 | 약 4.15 |
| B | 5, 10, 15 반복 | 30 | 10 | 약 4.15 |
평균 차이는 여전히 3이고, 데이터의 폭도 넓습니다. 하지만 샘플 수가 그룹당 30개로 증가하면서 p-value는 약 0.0070으로 작아집니다.
네 가지 예시 비교
| 예시 | A 그룹 | B 그룹 | Sample size | 평균 차이 | 데이터 폭 | p-value |
|---|---|---|---|---|---|---|
| 1 | 1, 2, 3 | 4, 5, 6 | 3 vs 3 | 3 | 좁음 | 약 0.0213 |
| 2 | 1, 2, 3 반복 | 4, 5, 6 반복 | 6 vs 6 | 3 | 좁음 | 약 0.00017 |
| 3 | 2, 7, 12 | 5, 10, 15 | 3 vs 3 | 3 | 넓음 | 약 0.503 |
| 4 | 2, 7, 12 반복 | 5, 10, 15 반복 | 30 vs 30 | 3 | 넓음 | 약 0.0070 |
이 예시를 통해 알 수 있는 점은 명확합니다.
p-value는 단순히 평균 차이가 얼마나 큰지만 보여주는 값이 아닙니다. 평균 차이, 샘플 수, 데이터의 흩어짐이 함께 반영됩니다.
다만 예시 2와 예시 4는 p-value의 계산 원리를 쉽게 보여주기 위해 동일한 숫자를 반복한 교육용 예시입니다. 실제 연구에서 같은 샘플의 값을 여러 번 복제해 행 수만 늘리는 것은 샘플 수를 증가시킨 것이 아닙니다.
Microbiome 연구에서는 서로 다른 대상자에게서 독립적으로 얻은 biological sample과 같은 샘플을 반복 측정한 technical replicate를 구분해야 합니다. 이를 구분하지 않으면 p-value가 과도하게 작아지는 의사반복(pseudoreplication) 문제가 발생합니다.
따라서 실제 결과를 해석할 때에는 p-value만 확인해서는 안 됩니다.
- 그룹 간 차이의 크기인 effect size를 함께 확인해야 합니다.
- 추정값의 불확실성을 보여주는 confidence interval도 함께 살펴봐야 합니다.
- 통계적으로 유의한 차이가 생물학적으로도 의미가 있는지 판단해야 합니다.
- 각 샘플이 서로 독립적인 biological sample인지 확인해야 합니다.
4. 그렇다면 검정력(Statistical power)이란 무엇인가
실제로 존재하는 차이를 통계 검정으로 발견할 수 있는 확률을 검정력(statistical power)이라고 합니다.
통계적으로는 1 - beta로 표현합니다. 여기서 beta는 실제로 차이가 있는데도 차이가 없다고 판단하는 오류의 확률입니다. 이를 제2종 오류(Type II error)라고 합니다.
일반적으로 연구를 설계할 때에는 80% 이상의 power를 목표로 삼는 경우가 많습니다.
Power는 다음 조건에 영향을 받습니다.
- Sample size: 샘플 수가 많을수록 실제 차이를 발견하기 쉬워집니다.
- Effect size: 그룹 간 차이가 클수록 발견하기 쉽습니다.
- 그룹 내부 분산: 같은 그룹 안에서 샘플 간 차이가 크면 그룹 간 차이를 구분하기 어려워집니다.
- 통계 검정 방법: 데이터에 적합한 검정을 사용해야 합니다.
- Microbiome diversity metric: 같은 데이터라도 선택한 metric에 따라 민감도가 달라질 수 있습니다.
따라서 “그룹당 샘플을 몇 개 모으면 충분한가?”라는 질문에는 하나의 정답이 없습니다.
비교하려는 그룹의 차이가 어느 정도인지, 그룹 내부 변동성이 얼마나 큰지를 함께 고려해야 합니다.
이제 논문의 simulation 결과를 살펴보면서 microbiome 그룹 비교에서 샘플 수와 통계적 유의성이 어떻게 연결되는지 정리해보겠습니다.
5. Beta diversity는 무엇을 비교하는가
논문의 Figure 4와 Figure 6을 살펴보기 전에 beta diversity의 개념을 간단히 정리해보겠습니다.
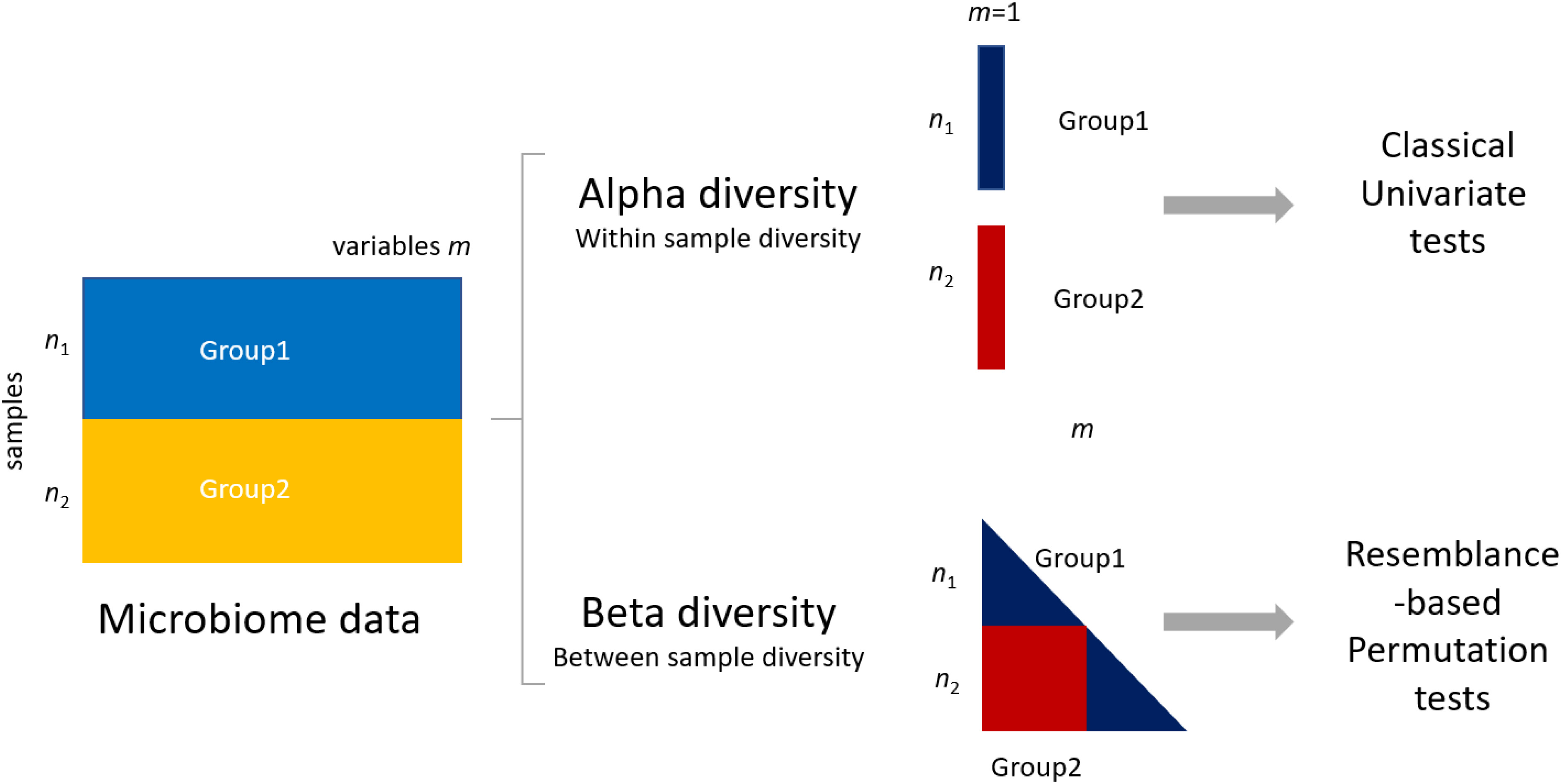
출처: Kers and Saccenti (2022), Figure 1, CC BY.
Alpha diversity는 하나의 샘플 내부에 존재하는 미생물 군집의 다양성을 하나의 값으로 요약합니다. 예를 들어 한 사람의 gut microbiome에 얼마나 다양한 미생물이 존재하고, 이들이 얼마나 고르게 분포하는지를 살펴봅니다.
반면 beta diversity는 샘플과 샘플 사이의 미생물 구성이 얼마나 다른지를 거리(distance)로 나타냅니다.
예를 들어 건강한 사람 30명과 질환자 30명의 gut microbiome을 비교한다면 각 샘플 사이의 거리를 계산합니다. 같은 그룹의 샘플끼리는 비교적 가깝고, 서로 다른 그룹의 샘플은 멀리 떨어져 있다면 두 그룹의 미생물 구성이 다를 가능성이 있습니다.
이 거리 정보는 PCoA plot과 같은 시각화에 사용할 수 있습니다. 통계적으로 그룹 간 차이를 평가할 때에는 흔히 PERMANOVA와 같은 permutation 기반 검정을 사용합니다.
여기서 중요한 점은 샘플 간 거리를 계산하는 방식이 하나만 있는 것은 아니라는 것입니다. 각 beta diversity metric은 서로 다른 정보를 중요하게 보기 때문에 같은 데이터에서도 결과가 달라질 수 있습니다.
| 존재 유무만 반영 | Abundance 반영 | |
|---|---|---|
| Phylogenetic 계통수 반영 X | Jaccard | Bray-Curtis |
| Phylogenetic 계통수 반영 O | Unweighted UniFrac | Weighted UniFrac |
간단히 정리하면 Jaccard와 unweighted UniFrac은 미생물의 존재 여부를 반영합니다. Bray-Curtis와 weighted UniFrac은 미생물의 양적 차이까지 반영합니다. UniFrac 계열은 여기에 미생물 사이의 phylogenetic 관계도 반영합니다.
이번 글에서는 Figure 4와 Figure 6을 이해하는 데 필요한 차이만 간단히 정리했습니다. Beta diversity metric의 특성과 선택 기준은 2편에서 조금 더 자세히 다뤄보겠습니다.
6. 같은 수의 샘플이라도 차이의 형태에 따라 결과가 달라집니다
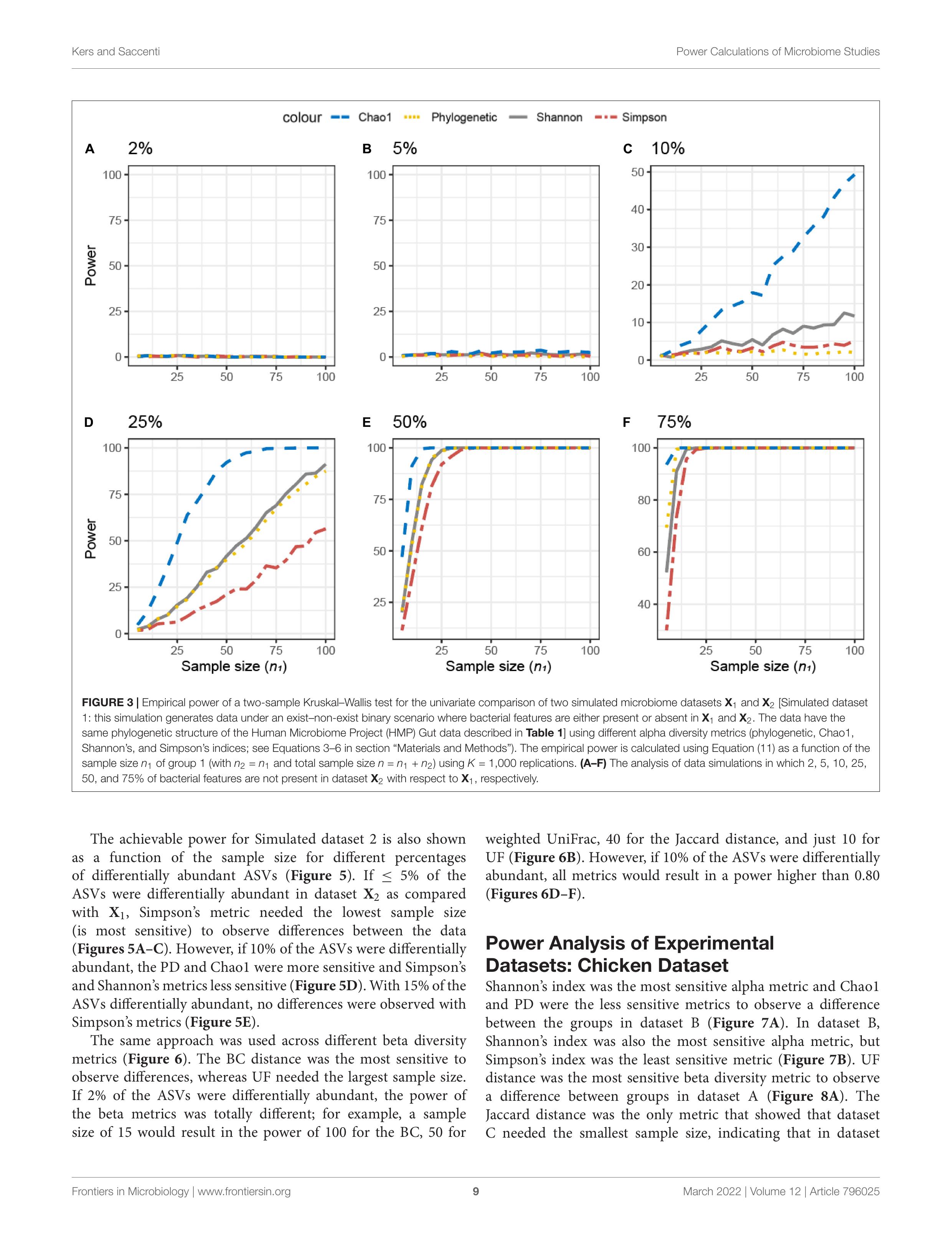
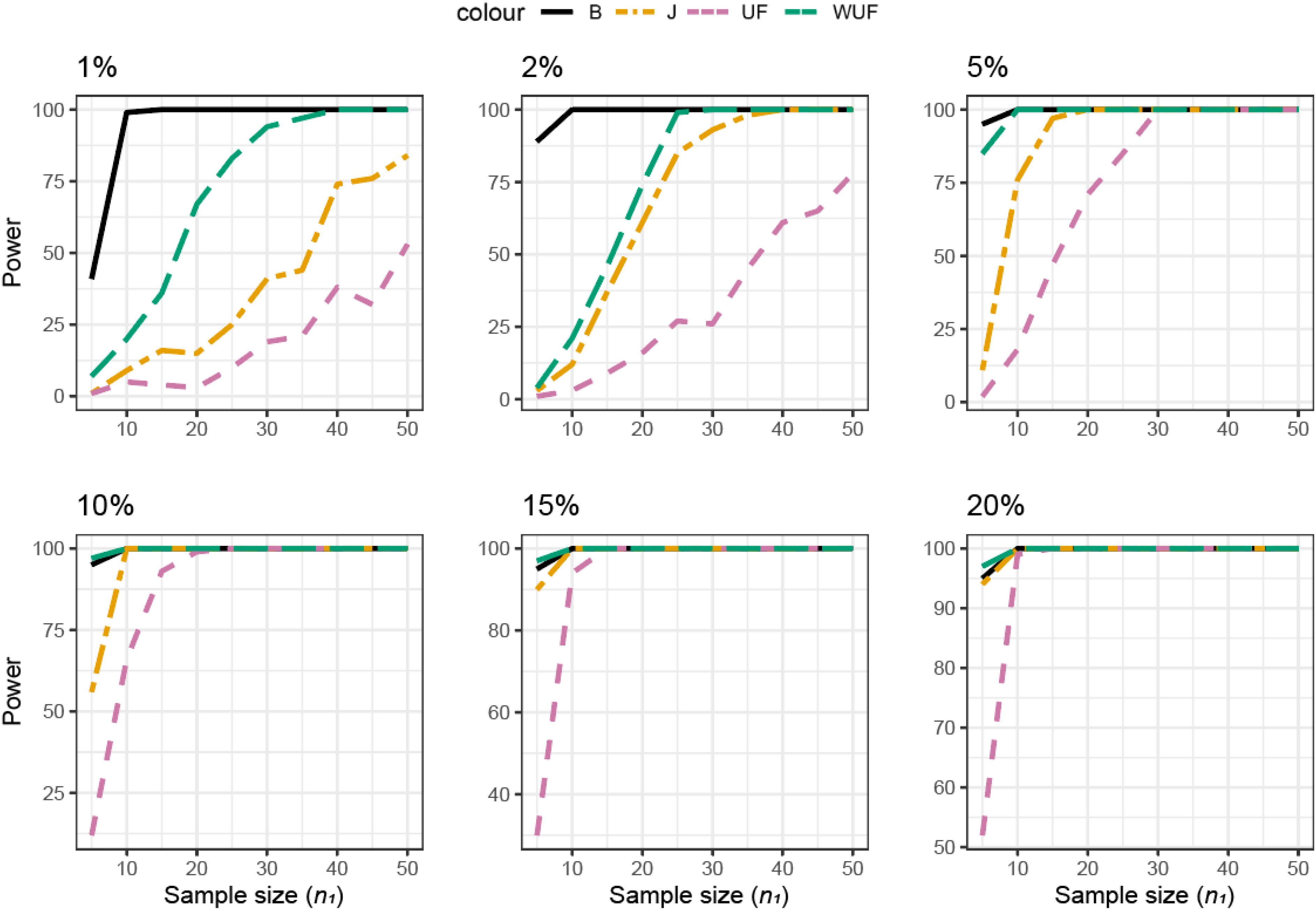
Figure 4. Presence / absence가 달라지는 경우
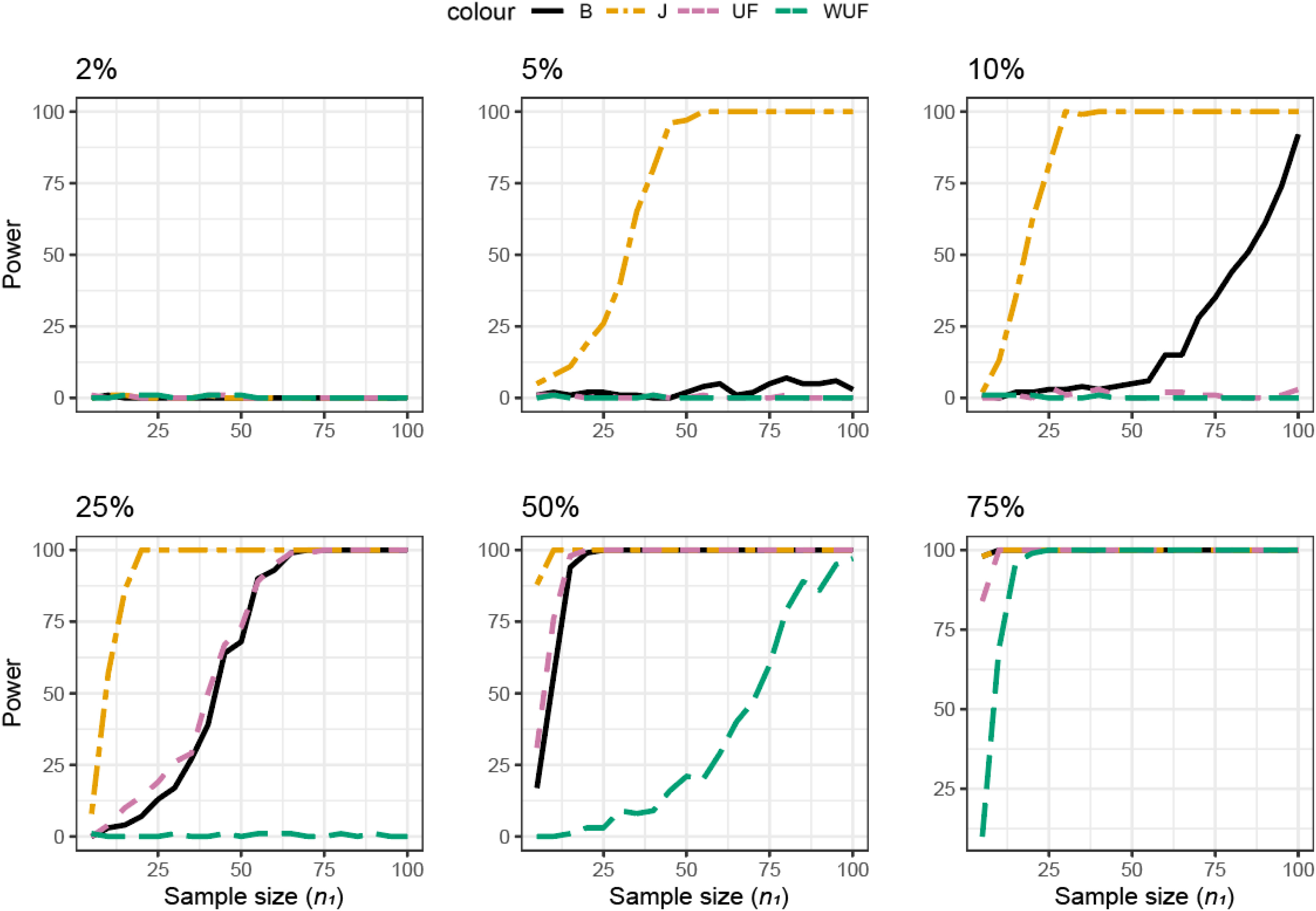
출처: Kers and Saccenti (2022), Figure 4, CC BY.
저자들은 HMP gut microbiome 데이터의 phylogenetic structure를 바탕으로 simulation 데이터를 만들었습니다. 이후 두 번째 그룹에서 일부 ASV가 존재하지 않도록 설정했습니다.
즉, 두 그룹의 미생물 구성에 차이를 인위적으로 만든 뒤, 그 차이를 통계적으로 발견할 수 있는지 확인한 것입니다.
그래프 상단의 숫자는 두 번째 그룹에서 제거한 ASV의 비율을 나타냅니다.
- 2%
- 5%
- 10%
- 25%
- 50%
- 75%
X축은 그룹별 샘플 수(sample size), Y축은 power입니다. 각 선은 서로 다른 beta diversity metric을 의미합니다.
- B: Bray-Curtis
- J: Jaccard
- UF: unweighted UniFrac
- WUF: weighted UniFrac
각 조건에서 그룹별 샘플 수가 증가할 때 statistical power가 어떻게 달라지는지 살펴보겠습니다.
먼저 전체 ASV 중 5%를 제거한 조건을 보겠습니다. Jaccard distance를 사용한 경우에는 다른 지표들과 달리 미생물의 존재 유무 차이를 더 잘 관찰할 수 있습니다. 그럼에도 약 80%의 Power를 확보하려면 한 그룹에 적어도 37~40개 이상의 샘플이 필요하다는 것을 보여줍니다.
하지만 Bray-Curtis, unweighted UniFrac, weighted UniFrac을 사용하면 상황이 다릅니다. 그룹당 100개의 샘플을 확보해도 power가 10%를 넘지 못합니다.
샘플을 많이 모았는데도 실제로 존재하는 차이를 거의 발견하지 못하는 것입니다.
이 결과를 보면 필요한 샘플 수를 단순히 숫자 하나로 정하기는 어렵다는 사실을 확인할 수 있습니다.
그룹당 100개라는 숫자는 microbiome 연구에서 언뜻 충분해 보입니다. 하지만 관찰하려는 차이의 형태와 분석 방법이 맞지 않으면 충분하지 않을 수 있습니다. 반대로 데이터 특성에 적합한 방법을 선택하면 더 적은 수의 샘플로도 차이를 확인할 수 있습니다.
Figure 6. Abundance가 달라지는 경우
Figure 4는 두 번째 그룹에서 일부 ASV를 제거한 simulation입니다. 즉, 특정 미생물이 있는지 없는지가 달라지는 상황을 보여줍니다.
그렇다면 두 그룹에 비슷한 종류의 미생물이 존재하지만 abundance가 달라지는 경우에는 어떤 결과가 나올까요?
저자들은 Figure 6에서 별도의 simulation을 진행했습니다. 이번에는 ASV를 제거하지 않았습니다. 대신 두 번째 그룹에 존재하는 ASV 가운데 4분의 1의 abundance를 증가시켰습니다.
출처: Kers and Saccenti (2022), Figure 6, CC BY.
각 패널은 해당 ASV의 abundance가 두 그룹 사이에서 얼마나 달라졌는지를 나타냅니다.
- 1%
- 2%
- 5%
- 10%
- 15%
- 20%
이번에는 Figure 4와 다른 결과가 나타납니다. Presence / absence 차이를 비교한 Figure 4에서는 Jaccard가 민감했지만, abundance 차이를 비교한 Figure 6에서는 Bray-Curtis가 가장 민감했습니다. (그래서 아마도 가장 많이 이용되는 지표중 하나지 않을까 싶습니다.)
예를 들어 일부 ASV의 abundance가 2% 증가한 조건에서 그룹당 샘플 수가 15개라면 Bray-Curtis의 power는 거의 100%에 도달합니다. 반면 weighted UniFrac은 약 50%, Jaccard는 약 40%, unweighted UniFrac은 약 10% 수준입니다.
같은 수의 샘플을 확보하더라도 관찰하려는 차이가 presence / absence인지 abundance인지에 따라 적합한 metric이 달라질 수 있습니다.
결국 “그룹당 몇 개의 샘플이 필요한가?”라는 질문은 “어떤 차이를 관찰하고 싶은가?”라는 질문과 함께 다뤄야 합니다.
7. 차이가 작을수록 더 많은 샘플이 필요합니다
차이가 작을수록 더 많은 샘플이 필요합니다. 라는 말은 너무나도 당연한 이야기입니다.
Figure 4에서 제거한 ASV의 비율이 10%, 25%, 50%로 증가하면 여러 metric의 power도 점차 증가합니다. Figure 6에서도 abundance 차이가 커질수록 여러 metric의 power가 증가합니다.
두 그룹의 차이가 크다면 비교적 적은 수의 샘플로도 차이를 발견할 수 있습니다. 반대로 차이가 작다면 훨씬 많은 샘플이 필요하거나, 특정 metric으로는 샘플 수를 늘려도 차이를 충분히 발견하지 못할 수 있습니다.
이것이 effect size를 함께 고려해야 하는 이유입니다.
연구를 설계할 때에는 단순히 선행 논문에서 사용한 sample size를 가져오는 것보다 다음 내용을 먼저 살펴봐야 합니다.
- 어떤 종류의 차이를 관찰하려는가?
- 예상되는 effect size는 어느 정도인가?
- 그룹 내부의 biological variation은 어느 정도인가?
- pilot data 또는 유사한 선행 데이터가 있는가?
- 사용할 분석 방법과 metric은 무엇인가?
그래서 저는 큰 비용과 시간이 소요되는 대형 코호트 연구를 시작하기 전에 사전 연구가 중요하다고 생각합니다. 사전 연구를 통해 그룹 사이의 차이와 변동성을 대략적으로 관찰한 뒤, 이를 바탕으로 적절한 sample size와 분석 방법을 결정하는 과정이 선행되어야 합니다.
8. 기존 microbiome 연구의 샘플 수는 충분했을까
저자들은 2020년 1월부터 2월까지 출판된 microbiome 관련 논문 100편도 검토했습니다.
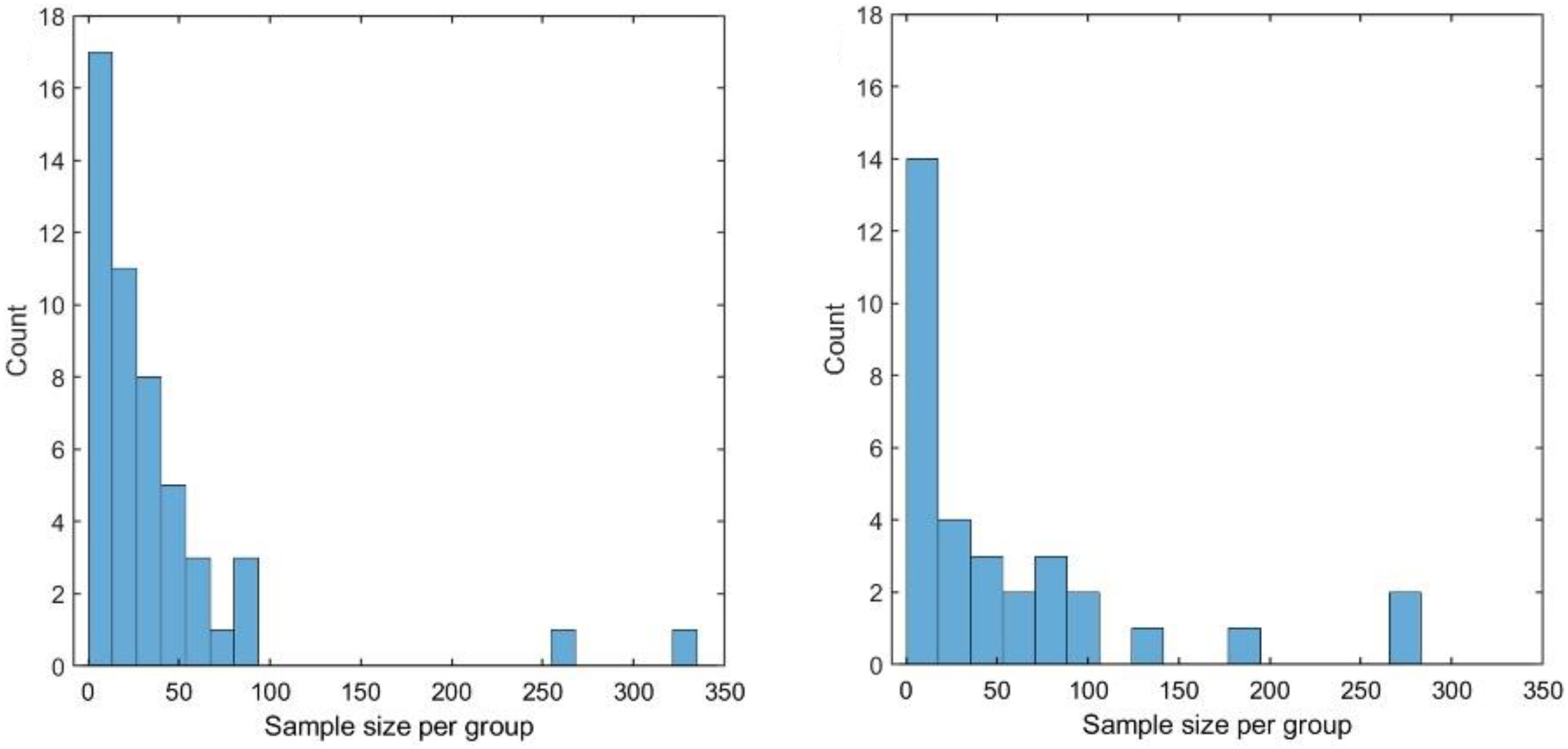
출처: Kers and Saccenti (2022), Figure 9, CC BY.
Chao1을 사용한 연구의 그룹별 sample size 중앙값은 39개였고, PERMANOVA를 사용한 연구의 중앙값은 22개였습니다.
논문에서 살펴본 실제 데이터에서는 그룹당 40개 미만의 샘플로 80% power에 도달하기 어려운 경우가 많았습니다. 물론 모든 연구에 동일한 기준을 적용할 수는 없습니다. 다만 기존 연구에서 사용된 샘플 수가 항상 충분했다고 보기도 어렵습니다.
또한 검토한 100편의 논문 중 effect size를 보고한 논문은 없었습니다. 샘플 수를 결정한 근거가 충분히 보고되지 않으면 연구 결과를 평가하기 어렵고, 후속 연구에서 power analysis를 수행하기도 어렵습니다.
9. 정리하며
“그룹당 몇 개의 샘플이 필요한가?”라는 질문에 모든 microbiome 연구에 적용할 수 있는 하나의 정답은 없습니다.
샘플 수가 많을수록 일반적으로 power는 증가합니다. 하지만 그것만으로 충분하지는 않습니다. effect size, 그룹 내부 분산, 통계 검정 방법, diversity metric을 함께 고려해야 합니다.
개인적으로는 분석을 시작하기 전에 아래 내용을 확인하는 것이 좋겠다는 생각이 들었습니다. 분석의뢰를 받을 때 항상 묻는 질문이기도 합니다.
- 무슨 샘플인가요? Fecal? 환경? : 왜냐하면 샘플 타입에 따라 기대하는 종 다양성이 달라지기 때문입니다.
- 샘플은 몇개인가요? : Statistical Power를 염려하기 때문입니다.
- 어떤 그룹을 비교하려고 하나요? : 단순히 두 그룹에 대한 비교인지, 시간에 따른 변화인지 통계방법을 달리해야하기 때문입니다.
- 함께 수집한 metadata에는 어떤 항목이 있나요?
- 관찰하려는 차이는 무엇인가요? : 분석을 시작하면서부터 결국 어떤 가설을 밝히고 싶은지, 무엇을 확인하고자 하는지 분명해야 합니다.
다음 글에서는 같은 논문을 바탕으로 alpha diversity와 beta diversity metric을 어떤 기준으로 선택해야 하는지 조금 더 자세히 정리해보겠습니다.
참고 논문
Kers, J. G., & Saccenti, E. (2022). The Power of Microbiome Studies: Some Considerations on Which Alpha and Beta Metrics to Use and How to Report Results. Frontiers in Microbiology, 12, 796025.
-2026.05.31 by Masanam-
댓글
내용에 대한 오류 수정 요청, 질문은 언제나 환영입니다. 자유롭게 댓글을 남겨주세요! (하지만 부적절한 댓글은 삭제될 수 있습니다)